
[알고리즘 특강] 1. STL
1. STL의 정의와 필요성
1.1 STL이란?
- 정의: C++의 표준 템플릿 라이브러리 (Standard Template Library)
- 역할: 데이터 구조와 알고리즘을 효율적으로 구현할 수 있는 도구 제공
1.2 STL의 주요 구성 요소
- Container - 임의 타입의 객체를 보관할 수 있는 컨테이너
- vector, list, set/map, deque, multiset/map, unordered_set/map, stack, queue, priority_queue 등
- Iterator - 컨테이너에 보관된 원소에 접근할 수 있는 반복자
- input/output iterators, forward/bidirectional iterators, random access iterators
- Algorithm - 반복자들을 가지고 일련의 작업을 수행하는 알고리즘
- sort, find, transform, for_each, generate, binary_search
참고 자료
- C++: https://en.cppreference.com/w/
- Java: java.lang.util Package
2. Sequence Containers
2.1 Sequence Containers의 특징
- 데이터를 순차적으로 저장하는 구조
- 구현이 단순하고 가볍고 빠름
- 저장할 데이터가 정렬 상태를 계속 유지할 필요 없다면 좋은 선택
주요 컨테이너: array, vector, deque, forward_list, list
3. Vector
3.1 Vector의 특징
- 메모리 상에서 데이터가 연속적으로 저장
- 배열의 크기를 runtime에 조절 가능
- 사용할 배열의 크기를 미리 알 수 있고 변하지 않는다면 array, 그렇지 않다면 vector를 선택

3.2 Vector의 구현
vector는 포인터 3개로 구현되어 있습니다:
- 할당된 배열의 시작 주소를 가리키는 포인터
- 다음에 데이터가 삽입될 위치를 가리키는 포인터
- 할당된 배열의 끝 주소를 가리키는 포인터
3.3 Vector의 주요 기능
- 데이터를 뒤에 삽입하면 2번 포인터에 삽입되고, 포인터가 1 증가
- iterator 멤버를 사용하면
begin(),end()함수 사용 가능 size(),capacity()함수로 데이터 개수와 할당된 크기 확인 가능- 임의의 위치에 있는 원소의 접근을 O(1)에 수행
- 맨 뒤에 새로운 원소 추가/제거 역시 O(1)에 수행
3.4 Vector 사용 예시
// vector 사용 예시 코드
#include <iostream>
#include <vector>
using namespace std;
int main() {
vector<int> vec;
vec.push_back(1); // 맨 뒤에 1 추가
vec.push_back(2); // 맨 뒤에 2 추가
vec.pop_back(); // 맨 뒤에 있는 데이터 제거
for(vector<int>::size_type i = 0; i < vec.size(); i++) {
cout << "vec의 " << i+1 << "번째 원소: " << vec[i] << endl;
}
}
3.5 Vector 데이터 삽입시 주의사항
push_back연산은 상수 시간복잡도를 가지나, 할당된 공간이 전부 차면 배열을 통째로 복사해 새로운 vector에 할당하는 reallocation이 발생해 시간이 많이 소요됩니다.- 따라서 알고리즘 문제 풀이 시에는 가급적 vector의 크기를 충분히 확보한 상태로 사용하는 것이 좋습니다.
- vector에서 임의의 위치에 원소를 추가하거나 제거할 때 시간복잡도는 O(n)으로 상당히 느립니다. 그 뒤에 오는 원소들을 한칸씩 이동시켜 줘야하기 때문입니다.
4. Deque
4.1 Deque의 특징
- container 앞, 뒤에 데이터를 빠르게 넣고 뺄 수 있는 double-ended queue
- 여러 개의 버퍼에 데이터를 나눠서 저장
- vector는 할당된 공간이 전부 차면 배열을 통째로 새로 할당하는 반면,
deque는 버퍼 하나만 할당하면 되므로 데이터 삽입이 언제든 O(1)
컨테이너의 앞과 뒤에 데이터 삽입/삭제 기능이 동시에 필요한 경우, deque는 유용한 선택이 됩니다.
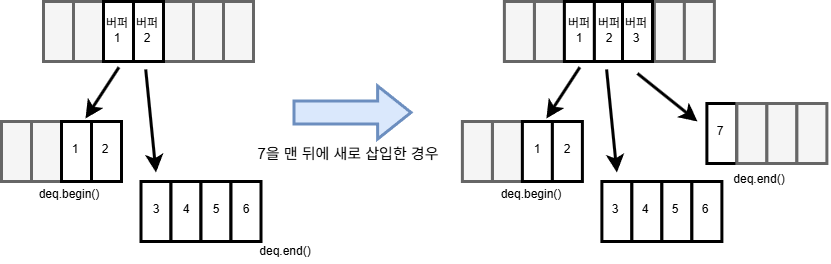
4.2 Deque vs Vector
vector의 원소들은 메모리상에 연속적으로 존재하는 것이 보장되지만,
deque는 원소들이 실제로 메모리 상에서 연속적으로 존재하지 않습니다.
이로 인해 원소들이 어디에 저장되어 있는지에 대한 정보를 보관하기 위해 추가적인 메모리가 더 필요합니다.
따라서 C배열의 라이브러리와 상호작용해야 하는 상황이거나, 공간지역성을 고려해야 하는 상황에서는
deque가 불리한 점이 있습니다.
4.3 Deque 사용 예시
// deque 사용 예시 코드
#include <iostream>
#include <deque>
using namespace std;
int main() {
deque<int> dq;
dq.push_back(1); // 맨 뒤에 1 추가
dq.push_back(2); // 맨 뒤에 2 추가
dq.pop_front(); // 맨 앞에 있는 원소 제거
}
5. List
5.1 List의 특징
- 양방향 연결 구조를 가진 linked list
- Container의 어느 위치에도 O(1)에 데이터 삽입/삭제 가능 (포인터를 갖고 있는 경우)
- 하지만 시작 원소와 마지막 원소의 위치만 기억하기 때문에 random access (Container의 i번째 데이터에 O(1)에 접근)
은 불가능
5.2 List 사용 예시
// list 사용 예시 코드
#include <iostream>
#include <list>
int main() {
list<int> mylist;
mylist.push_back(1); // push_back: 리스트 제일 뒤에 원소 추가
mylist.push_back(2);
mylist.push_front(0); // push_front: 리스트 제일 앞에 원소 추가
for(list<int>::iterator itr = mylist.begin(); itr != mylist.end(); ++itr) {
cout << *itr << endl; // 0 1 2 출력
}
return 0;
}
5.3 List의 Iterator 특징
list에서 iterator의 경우 ++, --와 같은 연산으로만 증감이 가능합니다.
다시 말해 오직 한칸씩만 움직일 수 있으며, itr + 2와 같이 임의의 위치에 있는 원소를 가리킬 수 없습니다.
6. List(forward_list)
6.1 Forward List의 특징
list는 doubly_linked list이고,std::forward_list는 singly-linked listsingly-linked list는 삽입과 삭제가 지정된 원소의 다음 원소에 한해서만 가능한 제약이 있지만,
doubly-linked list에 비해 포인터를 하나 덜 가지므로 기본적인 연산이 빠르고 메모리를 적게 사용- 만약
doubly-linked list의 기능까지 필요하지 않다면 더 가볍고 빠른forward_list가 좋은 선택
7. Associative Containers
7.1 Associative Containers의 특징
- 데이터를 정렬된 상태로 유지하는 자료구조
- 키(key)-값(value) 구조를 통해 요소에 빠른 접근은 가능하지만 삽입되는 요소의 위치를 지정할 수는 없음
- Red-Black Tree를 기반으로 하고 데이터의 추가/삭제/접근의 시간복잡도가
O(log n)
7.2 Red-Black Tree
자가 균형 이진 탐색 트리(self-balancing binary search tree)로서, 대표적으로는 연관 배열 등을 구현하는 데 쓰이는 자료구조입니다.
트리에 n개의 원소가 있을 때 O(log n)의 시간복잡도로 삽입, 삭제, 검색을 할 수 있으며 최악의 경우에도 우수한 실행 시간을 가집니다.
주요 컨테이너: set/map, multiset/multimap
8. Set / Map
8.1 Set의 특징
- 데이터 자체를 key로 사용
- 저장하는 값이 key가 되고 오름차순으로 정렬
- 검색 속도가
O(log N)이기 때문에 데이터의 존재 유무를 파악하는데 유용 (key 중복 허용 X)
8.2 Set 사용 예시
// set 사용 예시 코드
#include <iostream>
#include <set>
int main() {
set<int> myset;
myset.insert(1);
myset.insert(2);
set<int>::iterator itr;
itr = myset.find(2);
if(itr != myset.end()) {
// myset에 2가 있는 경우
} else {
// myset에 2가 없는 경우
}
}
8.3 Map의 특징
- (key, value) 쌍을 받아서 사용
- (key, value) 데이터를 묶어서 빠르게 검색할 때 유용
- 하나의 key에는 하나의 value만 연결 (key 중복 허용 X)
8.4 Map 사용 예시
// map 사용 예시 코드
#include <iostream>
#include <string>
#include <map>
using namespace std;
int main() {
map<string, int> mymap;
mymap["Tom"] = 20;
mymap["Sally"] = 23;
map<string, int>::iterator itr;
for(itr = mymap.begin(); itr != mymap.end(); itr++) {
cout << "key: " << itr->first << " value: " << itr->second << endl;
}
}
따라서:
- 단순히 데이터를 정렬 상태로 유지하고 존재 유무만 알고 싶다면
set을 - (key, value) 데이터 쌍을 key를 기준으로 정렬하고 싶다면
map을 사용하면 됩니다.
9. multiset / multimap
9.1 multiset/multimap의 특징
- 요소의 중복을 허용
- 같은 key를 여러 개 저장하고 싶을 때 사용
- multimap에서는 하나의 key가 여러 value와 연결될 수 있음
9.2 시간복잡도 주의사항
- set에서 key의 개수를 세거나, key를 지우는 함수는 모두 O(log n)입니다.
- multiset에서는 같은 key를 모두 세고, 모두 지우므로 O(log n + (같은 key를 가지는 데이터의 개수)) 만큼의 시간이 듭니다.
9.3 multiset 사용 예시
// multiset 사용 예시 코드
#include <iostream>
#include <set>
int main() {
multiset<int> myset;
myset.insert(2);
myset.insert(1);
myset.insert(2);
myset.insert(3);
// set은 1 2 3 출력, multiset은 1 2 2 3 출력
for(auto& i : myset) {
cout << i << std::endl;
}
}
10. Unordered Associative Containers
10.1 Unordered Containers의 특징
- 해시값을 사용해 데이터를 저장하는 구조
- 대부분의 경우에서 데이터의 추가/삭제/접근이 O(1)이므로 Associative Container보다 효율적
- 하지만 데이터를 정렬된 상태로 유지해야 하거나 (무수히 많은 key 값들로 인해) 해시 충돌이 걱정되는 상황이라면 Associative Container를 사용하는 것이 좋음
주요 컨테이너: unordered_set/map, unordered_multiset/multimap
11. Unordered_set / map
11.1 Unordered_set/map의 특징
- Data를 중복 없이 저장하고 싶고, Data의 순서가 상관없을 때 Associative Container 대신 사용 가능
11.2 unordered_map의 데이터 저장 방식

기본으로 사용하는 hash function은 hash이고, hash에서 기본으로 지원하는 타입은 int, double 등의 primitive type과 string 등이 있습니다.
12. Unordered_multiset / multimap
12.1 Unordered_multiset/multimap의 특징
- Associative Container 때와 마찬가지로, 같은 key를 가진 데이터를 중복으로 가져야 할 때 사용
- set, map의 경우 원소들이 순서대로 정렬되어서 저장되지만,
unordered_set, unordered_map은 원소들이 순서대로 정렬되어서 저장되지 않음
12.2 Unordered_set 사용 예시
// unordered_set 사용 예시 코드
#include <iostream>
#include <unordered_set>
int main() {
unordered_set<int> myset;
myset.insert(5);
myset.insert(2);
myset.insert(10);
myset.insert(4);
myset.insert(300);
myset.insert(77);
// 77 5 10 2 4 300 모든 원소를 iterator를 사용하여 출력해보면 정렬되지 않은 채 랜덤하게 나옵니다.
for(auto& i : myset) {
cout << i << endl;
}
}
13. Container adaptors
13.1 Container adaptors의 특징
- 기존 Container를 변경하여 특정 인터페이스만을 제공
13.2 Stack
- LIFO (Last-In, First-Out) 자료구조로 순차 컨테이너를 기반으로 구현
- default 기반 컨테이너는 deque
- push(저장), pop(삭제), top(접근) 함수를 사용하며 순차 컨테이너의 한 끝에서만 모든 연산이 적용
13.3 Queue
- FIFO (First-In, First-Out) 자료구조로 순차 컨테이너를 기반으로 구현
- default 기반 컨테이너는 deque
- front(접근) 함수를 사용하며 순차 컨테이너의 한 끝에서만 저장이 가능하고 반대쪽 끝에서는 데이터 삭제만 가능
- (정의:
template<class T, class Container = deque> class queue)
13.4 Priority Queue
- 순차 컨테이너를 기반으로 구현
- default 기반 컨테이너는 vector
- Container를 max heap으로 유지
- push(저장), pop(삭제), top(접근) 함수를 사용하며 데이터의 우선순위가 큰 순서대로 접근 가능
14. 문제
- 수열 편집
- 메모장 프로그램
댓글남기기